-
딥러닝 #1 (작동 구조, 기울기 소멸 문제, 과적합 문제)인공지능 2021. 1. 31. 16:38
"
최근 '알파고'부터 시작하여 '이루다 AI 챗봇'에 이르기까지 딥러닝 모델에 대한 발전과 관심이 점점 커져 왔다.
하지만 개인 정보 및 사생활 침해 문제들과 미래의 일자리가 뺏길 것에 대한 우려의 목소리들 역시 커지고 있는 상황이다.
대부분의 우려는 오해로부터 발생하는 것으로, 오해를 바로잡기 위해선 개략적으로 시스템을 이해해 볼 필요가 있다.
이번엔 딥러닝 모델의 기본 구조가 어떻게 되어있고 딥러닝 모델을 개발함에 있어 기본적으로 해결해야 할 문제점에 대해 논해 보겠다.
"
<본 글은 머신러닝에 대한 기본적인 학습을 전제로 함>딥러닝이란 여러 층으로 이루어진 인공 신경망을 사용하여 머신러닝 학습을 수행하는 방식이다.
머신러닝 범주 안에 존재하는 학습 방식이지만 "층의 개수가 머신러닝보다 훨씬 많다는 점(최소 3층 이상)"과 "입력 데이터 중 학습에 적용할 특징 벡터를 자체 추출한다는 점"에서 딥러닝만의 차별점이 발생한다.

AI 범주 내 소속도 "딥러닝 모델의 기본 구조"

복잡성의 차이가 있을 뿐 기본 구조는 머신러닝과 동일하다. 기본 작동 구조는 다음과 같다.
1. 입력 데이터 벡터 X는 층을 거칠 때마다 파라미터(가중치)가 곱해지고 활성화 함수가 적용되면서 변환
2. 최종 출력된 예측 값에 대해 실제 값과의 차이를 적당한 오차 함수(손실 함수)로 표현
3. 적당한 최적화 기법을 통해 오차 역전파를 발생시켜 오차 함수를 최소화시키는 방향으로 가중치 조정
머신러닝과 똑같은 메커니즘이라고 느껴지는 것이 정상이다. 하지만 그렇다고 머신러닝과 똑같은 활성화 함수와 최적화 기법을 사용할 경우 의미 있는 학습 결과를 내기는 힘들 것이다. 그 이유는 가중치 조정 과정에 있다.
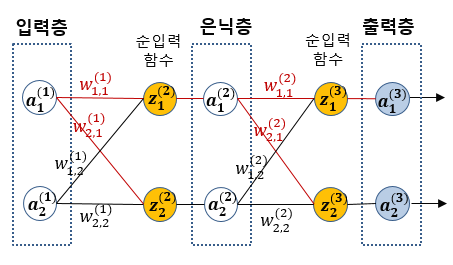

은닉층이 한 개인 간단한 신경망에서의 가중치 조정을 예시로 들겠다. 은닉층과 출력층 사이 첫번째 가중치 벡터 W1,1 (2)를 조정하는 경우를 보겠다.
오차 함수에 해당 가중치가 기여한 정도 (편미분항)에 학습률을 곱하여 조정해 나간다.

φ는 활성화 함수를 의미 즉 새로 조정된 가중치의 학습항은 활성화 함수의 도함수 값이 중요하게 작용하게 된다.
지금은 간단한 신경망의 출력층 직전 가중치를 조정하였기에 미분항이 하나지만, 만약 층이 깊어진다면 입력층에 가까운 가중치의 학습항은 활성화 함수의 미분 값으로 도배가 될 것이다.
문제는 여기서 발생한다.
"기울기 소멸 문제"
머신러닝에서 자주 쓰이는 활성화 함수를 두가지 고르라면 '시그모이드 함수'와 'tanh 함수'이다. 이 두 함수의 특징은 기울기가 1보다 작은 값에서 머문다는 것이다.
이 활성화 함수를 딥러닝 모델에 사용할 경우 위에서 언급한 상황, 즉 활성화 함수의 미분 값이 많이 곱해지면 곱해질수록 학습항의 크기는 0에 수렴하게 된다.

입력층에 가까운 가중치는 조정되지 못하는 문제를 '기울기 소멸 문제' 라고 일컫는다. 이 문제로 인해 심층신경망 모델에서는 ReLU 함수를 가장 많이 사용한다.

ReLU 함수는 입력값이 음수면 0을 출력하고, 양수일 경우 입력 값을 그대로 출력하는 함수로 기울기가 0 혹은 1 이라는 특징을 지니고 있다.
이 특징이 기울기 소멸 문제를 완화시켜 주기에 딥러닝 모델에서 가장 많이 사용된다. 뿐만 아니라 입력 값과 출력 값 사이 관계를 0과 1의 선형 관계로 표현해주기 때문에 계산 속도를 월등히 높여준다.
이제 모든 가중치에 대한 학습이 가능하고 또 그 속도까지 빨라졌으니 최고의 학습 결과가 나오길 기대해 볼 수도 있겠으나 한가지 문제를 더 해결해야 한다.
모델의 가중치가 학습 데이터에 지나치게 맞추어지면서 복잡도가 증가할 경우, 새로운 데이터에 대해 오히려 올바른 판단을 하지 못하게 되는
"과적합 문제"
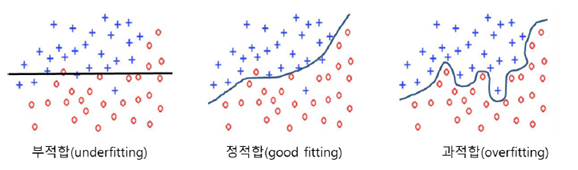
위 문제를 해결하기 위해 3가지 정도의 기법을 제시할 수 있다.
- 규제화 기법
- 드롭아웃 기법
- 배치 정규화 기법
먼저 규제화 기법은 오차 함수에 모델 복잡도를 벌점 항으로 추가하여 복잡도를 낮추고 과적합을 피하는 기법으로, 주로 가중치의 크기들의 합을 이용하여 벌점 항을 정의한다.
가중치의 크기들의 합으로 표현하는 이유는 특정 가중치의 값이 다른 것들에 비해 지나치게 큰 값이 될 경우, 이 가중치에 의한 영향이 과도하게 커지는 과적합 현상이 발생하기 때문이다.
드롭아웃 기법은 딥러닝 신경망에서 과적합 문제에 대응하기 위해 사용하는 대표적인 방법으로, 무작위로 일부 노드의 가중치 연결선을 끊고 학습하는 기법이다.
부정확도를 일부러 높여서 오차에 대한 민감도를 낮추어 특정 가중치의 폭발적인 증가 없이 전체적인 학습이 가능하다는 특징이 있다.
마지막으로 배치 정규화 기법의 경우 미니 배치와 내부 공변량 변화에 대한 이해가 필요하다.
미니 배치란 전체 학습 데이터를 일정 크기로 나누어 놓은 것을 말한다. 미니 배치 단위 별로 학습이 이루어지게 되는데, 미니 배치 내 학습 데이터 각각에 대한 그레디언트를 구한 다음 평균을 계산하여 가중치를 변화시킨다.
특정 그레디언트가 매우 클 경우 해당 가중치가 매우 높게 조정되는 현상을 방지해준다는 특징이 있다.

내부 공변량 변화란 이전 층들의 학습에 의해 가중치 값이 변하게 되면 현재 층에 전달되는 입력 데이터의 분포가 현재 층이 학습했던 시점의 분포와 차이가 발생하는 문제를 말한다.

학습 시점의 차이로 인해 현재 층이 학습했던 데이터 분포가 아닌 새로운 데이터 분포가 입력되는 상황 이런 내부 공변량 변화는 층마다 입력 데이터 셋의 불균형을 초래하여 그레디언트 폭발을 유발하고, 이는 곧 특정 가중치의 크기를 너무 크게 조정하여 복잡도를 높이는 결과로 이어진다.
이를 방지하기 위해 입력 데이터 분포를 정규화시키는 작업이 필요하고 이게 바로 배치 정규화 기법이다.
배치마다 가중치 연산을 적용한 입력 값과 활성화 함수가 적용된 출력 값이 정규 분포를 이루도록 하는 기법으로 활성화 함수가 적용되기 전 먼저 정규 분포를 만든다.

입력 값과 출력 값 사이 노드에서 평균과 편차를 계산 후 조정이 이루어지는 과정 이렇게 입력 데이터 셋의 분포를 조정할 경우,
전체적인 데이터의 분포를 모아주기 때문에 학습률의 값을 너무 작게 하지 않더라도 해를 놓칠 일이 적어지며 (이는 곧 학습 속도를 높여준다)
특정 가중치의 폭발적인 성장을 억제하기 때문에 과적합을 손쉽게 억제할 수 있다.
'인공지능' 카테고리의 다른 글
딥러닝 #3 생성모델 part 1 Boltzmann Machine (1) 2021.03.08 딥러닝 #2 (CNN 구조, CNN 학습 알고리즘) (1) 2021.02.17 서포트 벡터 머신(Support Vector Machine) (0) 2020.12.20